A new extension to Zarr just landed: the rectilinear chunk grid lets you specify arbitrarily sized chunks along each axis, aligning chunk boundaries with the natural structure of your data instead of forcing a regular grid.
How we built a Slack bot that alerts our team when it's snowing at their location, using Earthmover's Marketplace and Flux APIs to skip the data pipeline entirely.
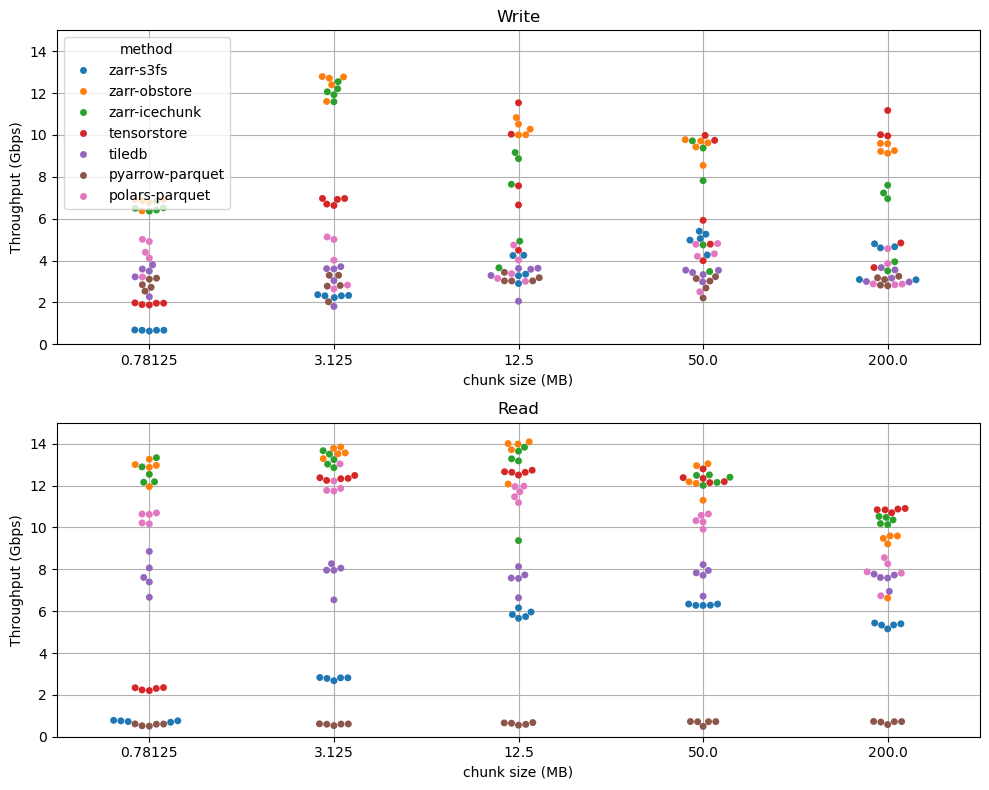
Zarr Python with Icechunk or Obstore now fully saturates the network between EC2 and S3, achieving the physically maximum possible throughput for reading and writing tensor data in the cloud. Benchmarks compare Zarr, Tensorstore, TileDB, and Parquet stacks across a range of chunk sizes and instance types.
A roadmap for integrating Xarray and napari to deliver named-dimension-aware, metadata-rich scientific data visualization across biology and geosciences.
Earthmover co-organizes the Zarr Summit in Rome, bringing together developers and adopters to advance the open-source cloud-native array format as adoption accelerates across major organizations like ESA, NASA, and NVIDIA.
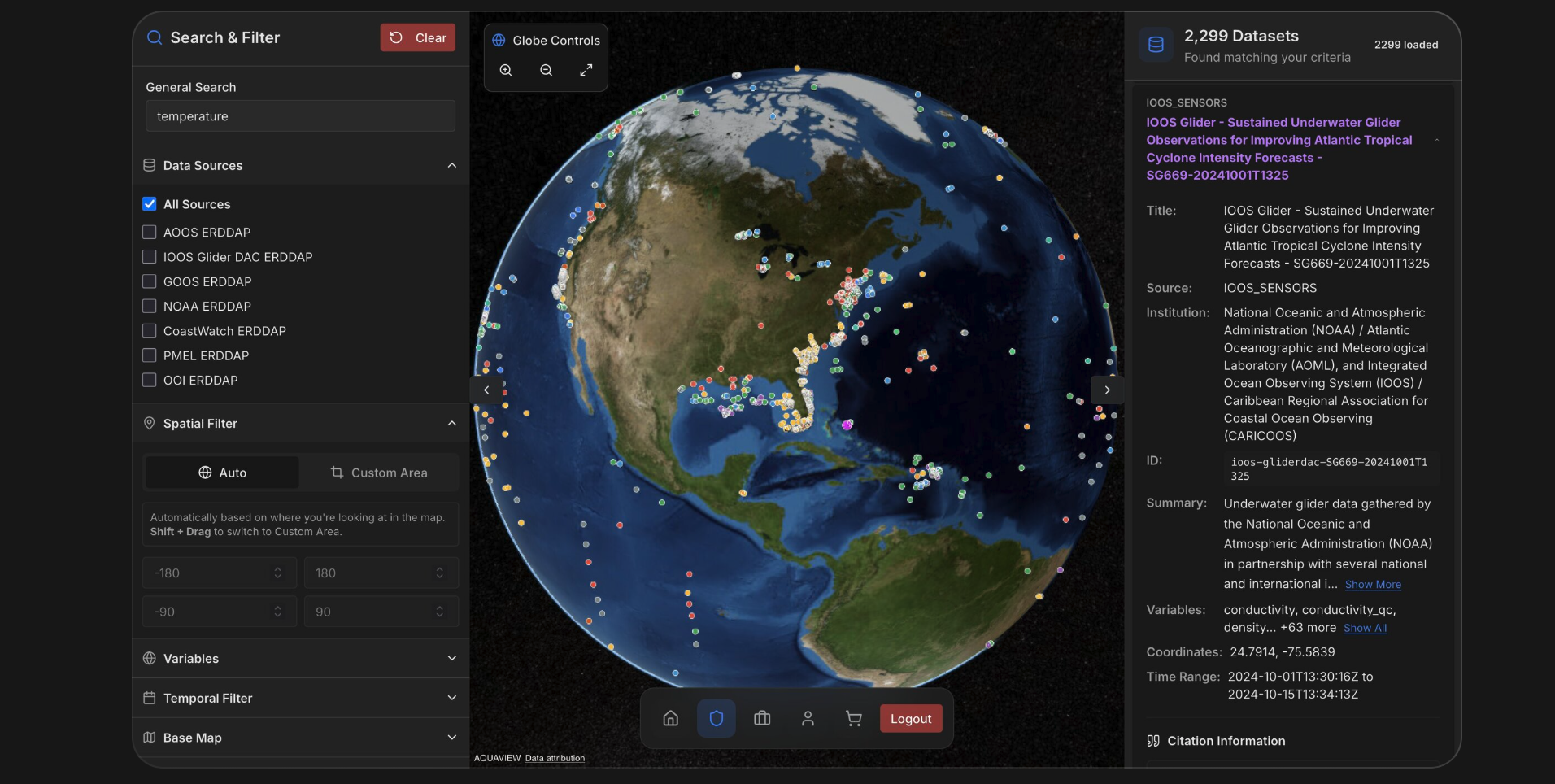
Woods Hole scientists reduced ocean profile data access from 10 minutes to 10 seconds by converting their OPeNDAP-served NetCDF files to Icechunk repositories on AWS S3.
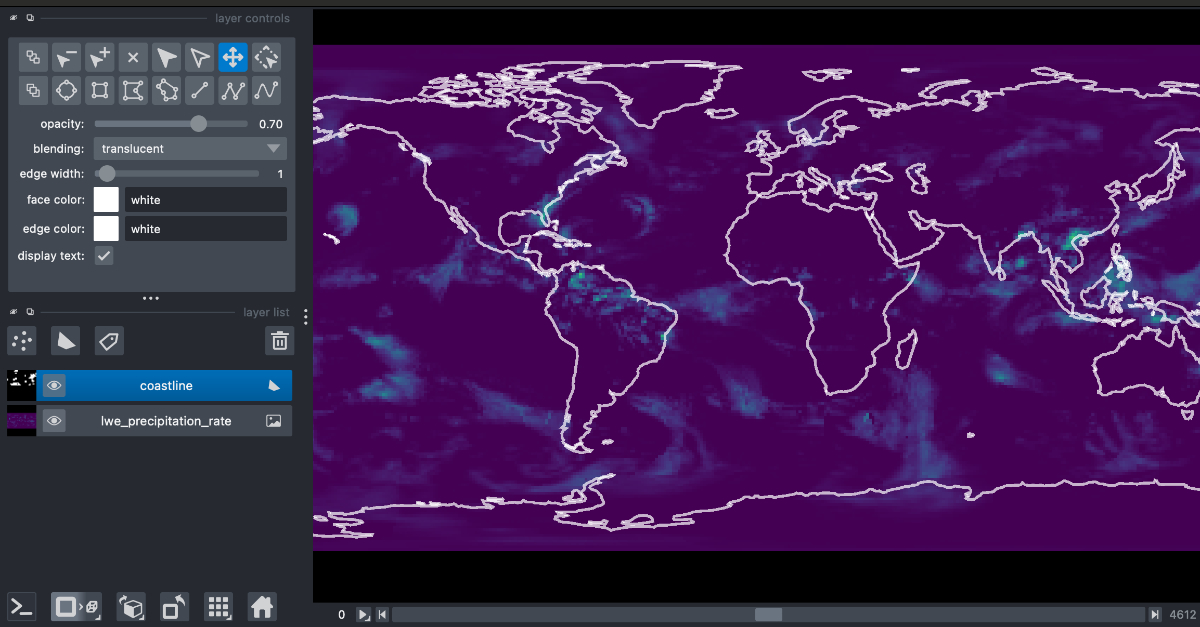
Earthmover is launching a new open-source library xpublish-tiles that powers our new Flux Tiles service, which allows Earthmover Platform users to view their data on a slippy map with dynamically rendered tiles at lower zoom levels than was possible previously.
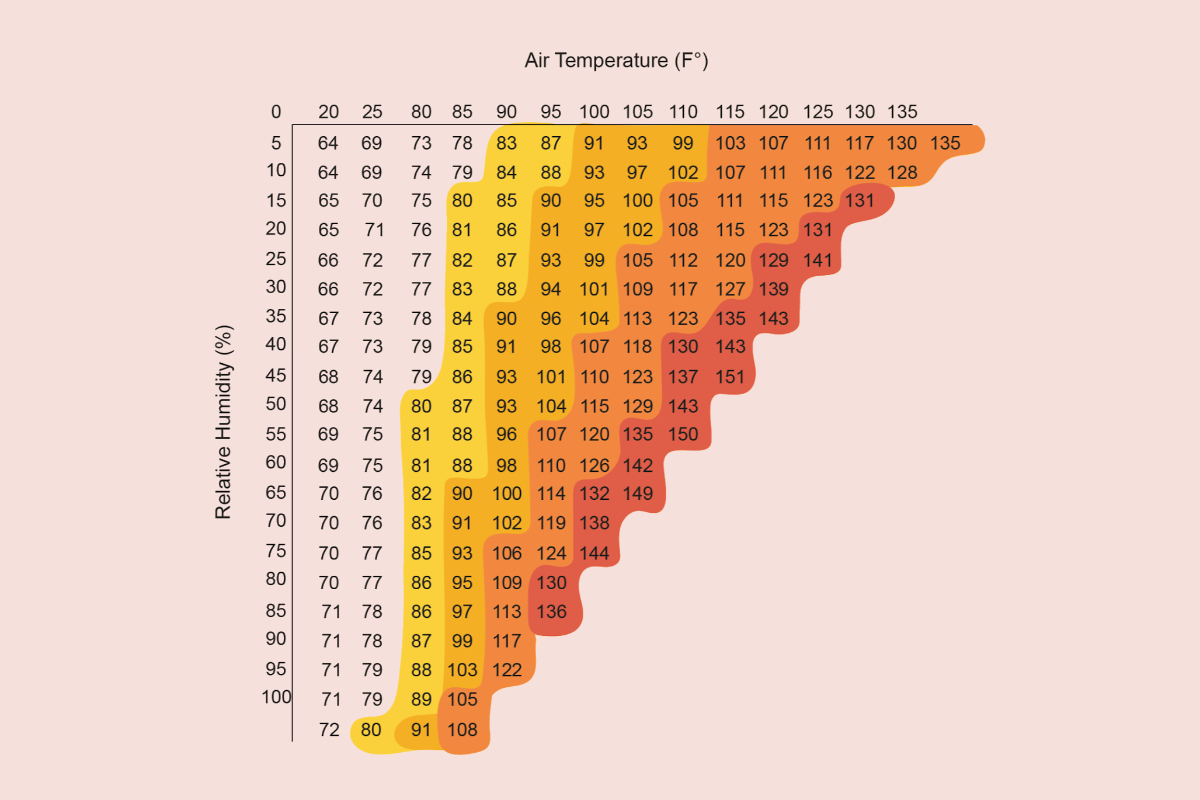
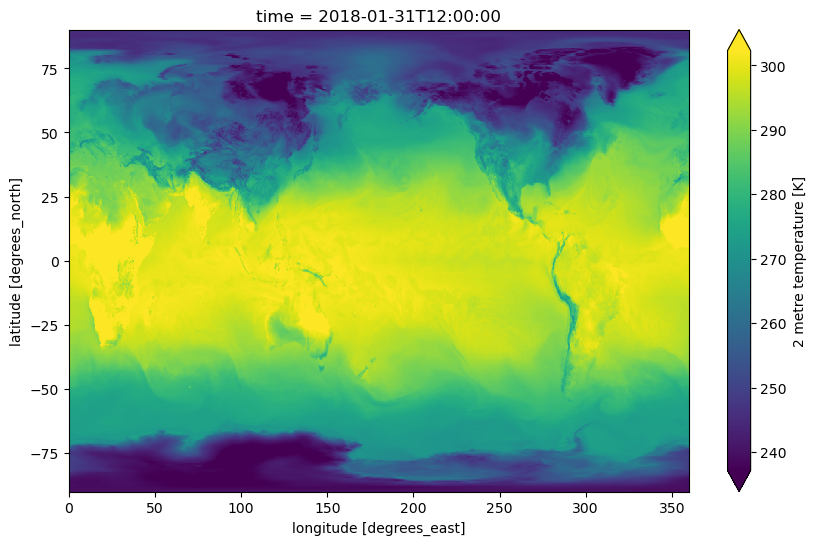
A hands-on walkthrough of calculating historical heatwave frequency over NYC using ERA5 reanalysis data on the Earthmover platform with Arraylake, Icechunk, Xarray, and open-source climate tools.
GPUs running AI weather forecasts spend over 95% of their time idle, waiting for data. Three optimizations — pre-processing inputs into Icechunk, moving regridding onto the GPU, and writing outputs in parallel — cut inference costs by nearly 90%.
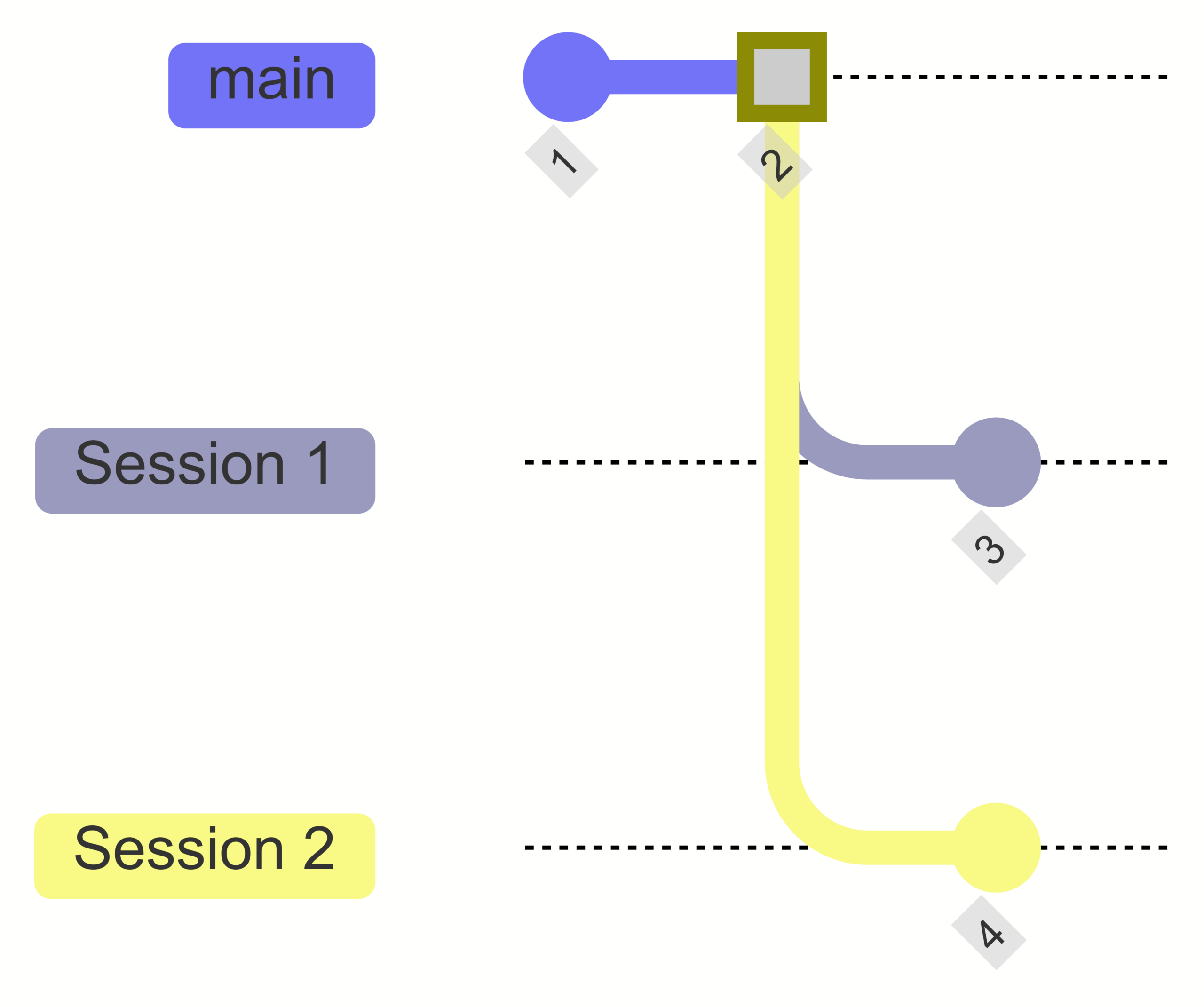
Zarr lacks built-in support for concurrent readers and writers, leading to inconsistent reads and conflicting writes in team settings. Icechunk solves this by adding atomic updates, consistent snapshots, and Git-like version control on top of Zarr.
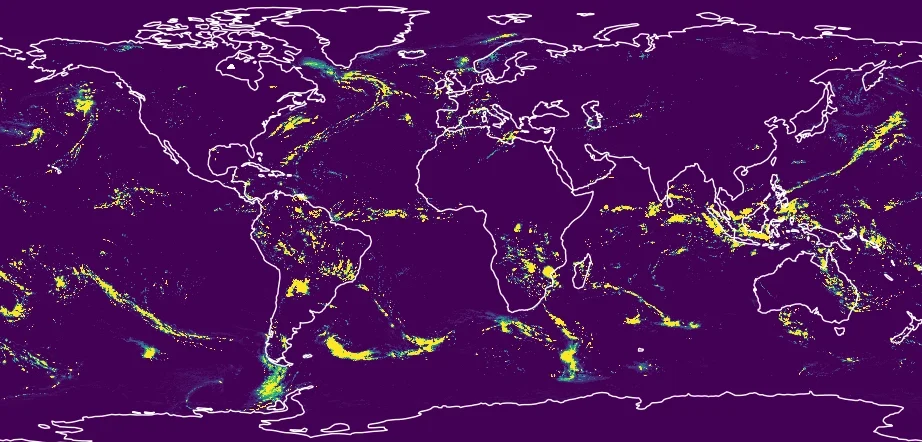
Introducing the Radar DataTree, a new data model that organizes thousands of fragmented weather radar scans into a single time-aware, cloud-native, version-controlled dataset using xarray-datatree, Zarr, and Icechunk.
Earthmover is sponsoring Ocean Hack Week 2025, providing financial support for participant travel and an Arraylake organization to empower the open ocean science community.
An introduction to the WMO FM-301 standard for weather radar data and how open-source tools like Xradar are turning fragmented binary radar files into structured, analysis-ready datasets.
Weather radar captures rich four-dimensional atmospheric data, but legacy binary formats and fragmented archives make large-scale analysis painfully difficult. A modern, cloud-native data model could unlock radar's vast scientific potential.
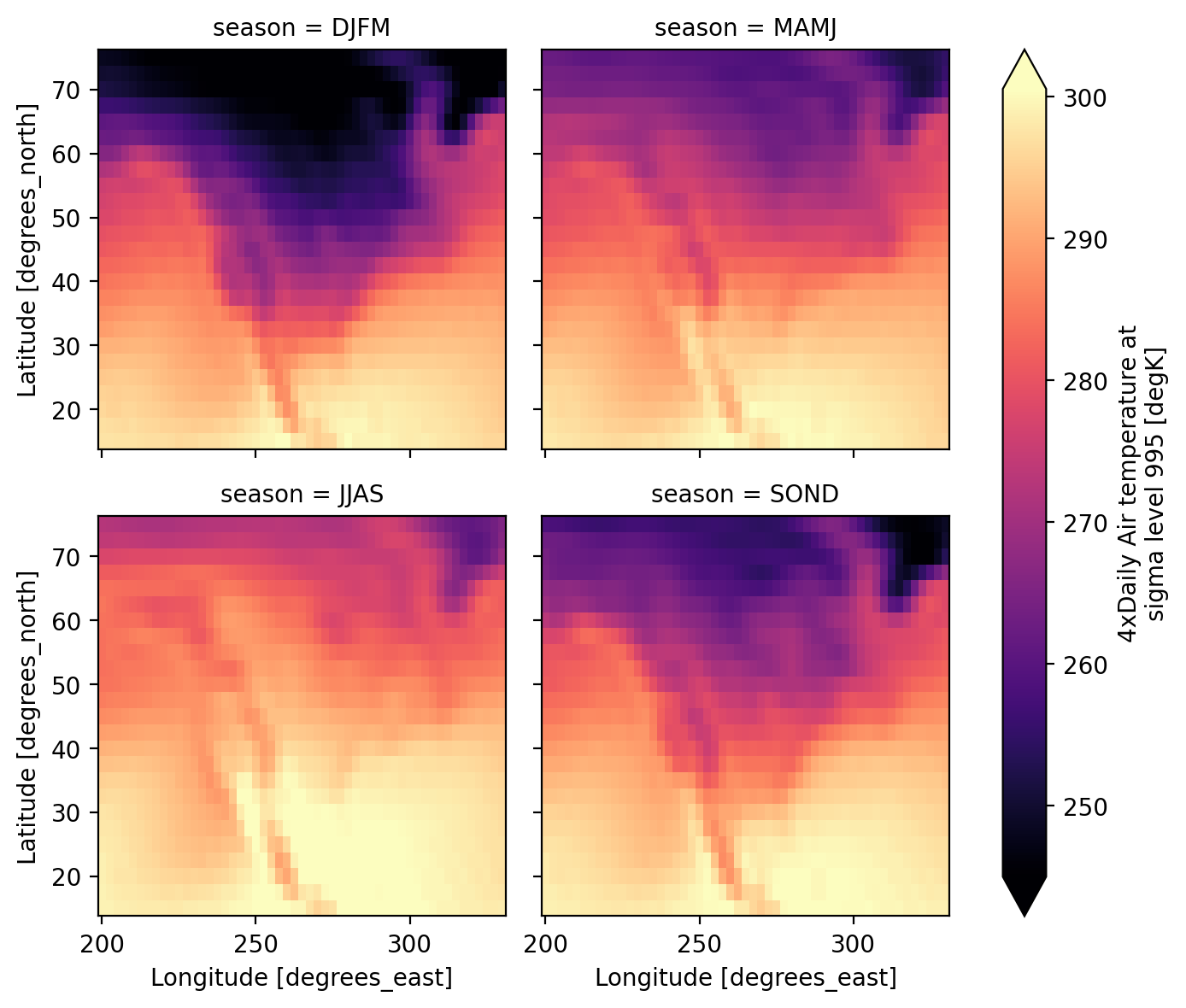
Xarray introduces SeasonGrouper and SeasonResampler, two new Grouper objects that enable custom, overlapping, and variable-length seasonal aggregations without workarounds.
Open-data practice in ocean/atmosphere sciences is approximately 170 years old! While it is easy to exclaim, "weather/climate are global, of course we must share data", the actual story is anything but. That story holds valuable inspiration that we can draw from as we face a significant reduction in US climate science research.
Xarray's labeled, multidimensional data structures can solve common pain points in biological data analysis, from tracking microscopy metadata to managing complex genomic datasets. Adoption has been limited by awareness, technical rough edges, and lack of tool integration, but the community is actively working to change that.
A practical guide to Icechunk's garbage collection and expiration operations, explaining when and how to safely reclaim storage from unused snapshots and dangling objects.
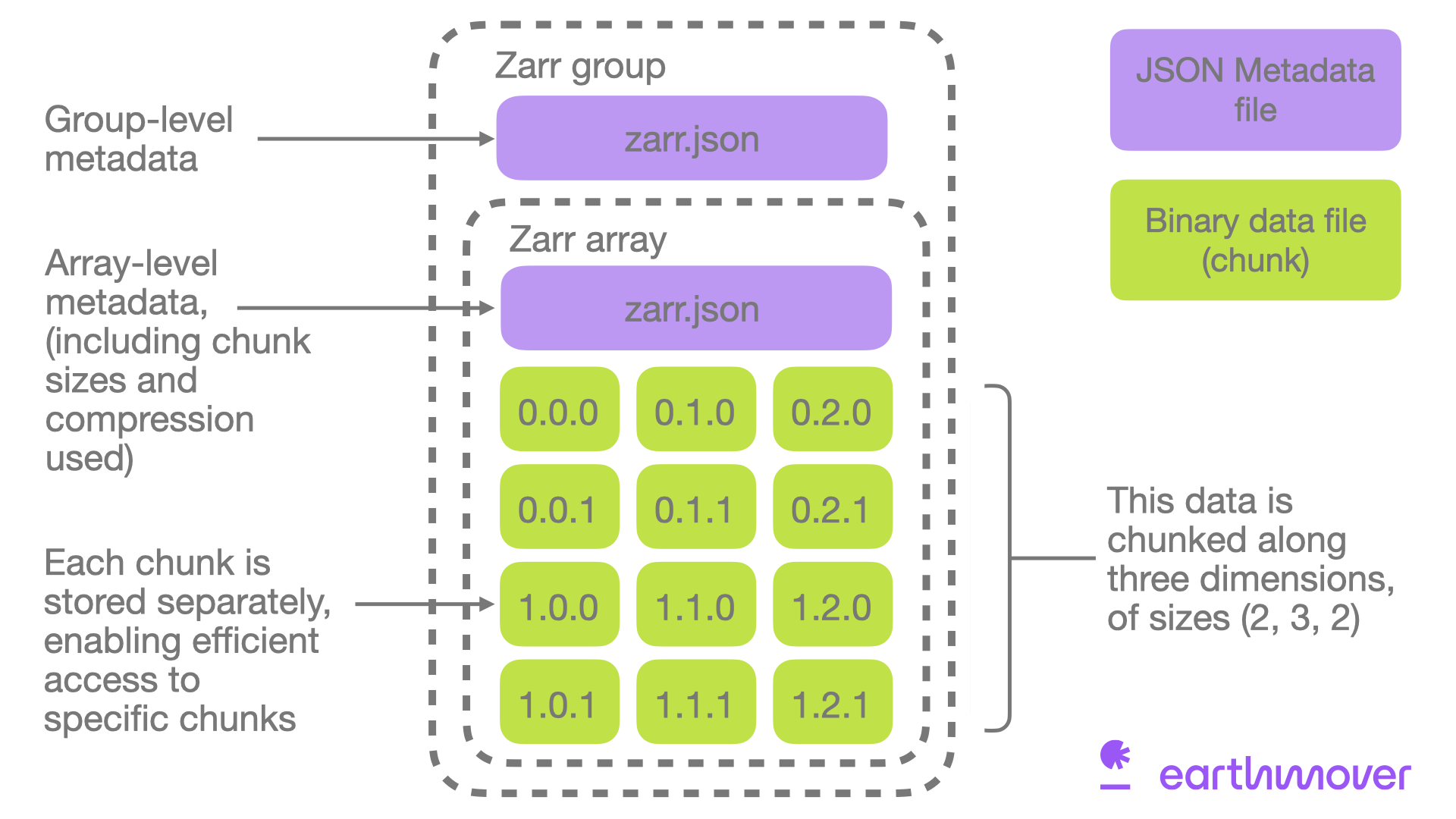
Zarr is an open-source, cloud-native protocol for storing chunked, compressed N-dimensional arrays. This guide covers how Zarr works, its ecosystem of tools like Xarray and Icechunk, and when to use it for large-scale scientific and ML data.
Icechunk stores versioned array data efficiently by never copying or rewriting existing chunks, so each new version only consumes storage for the data that actually changed. Older versions can be expired and garbage-collected when they are no longer needed.
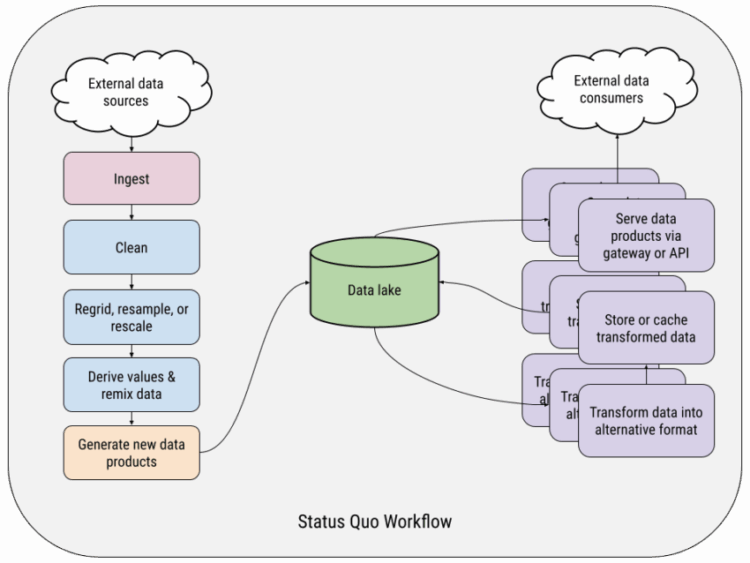
Scientific data pipelines are plagued by data swamps, duplicated code, fragile workflows, and siloed teams. TensorOps is a vision for modern practices that bring collaboration, velocity, and reliability to scientific data engineering.
At the 2025 Cloud-Native Geospatial conference, Zarr adoption was surging across the geospatial domain, with Copernicus Sentinel, USGS Landsat, Google Earth Engine, and ESRI ArcGIS all embracing the format for cloud-optimized array data.
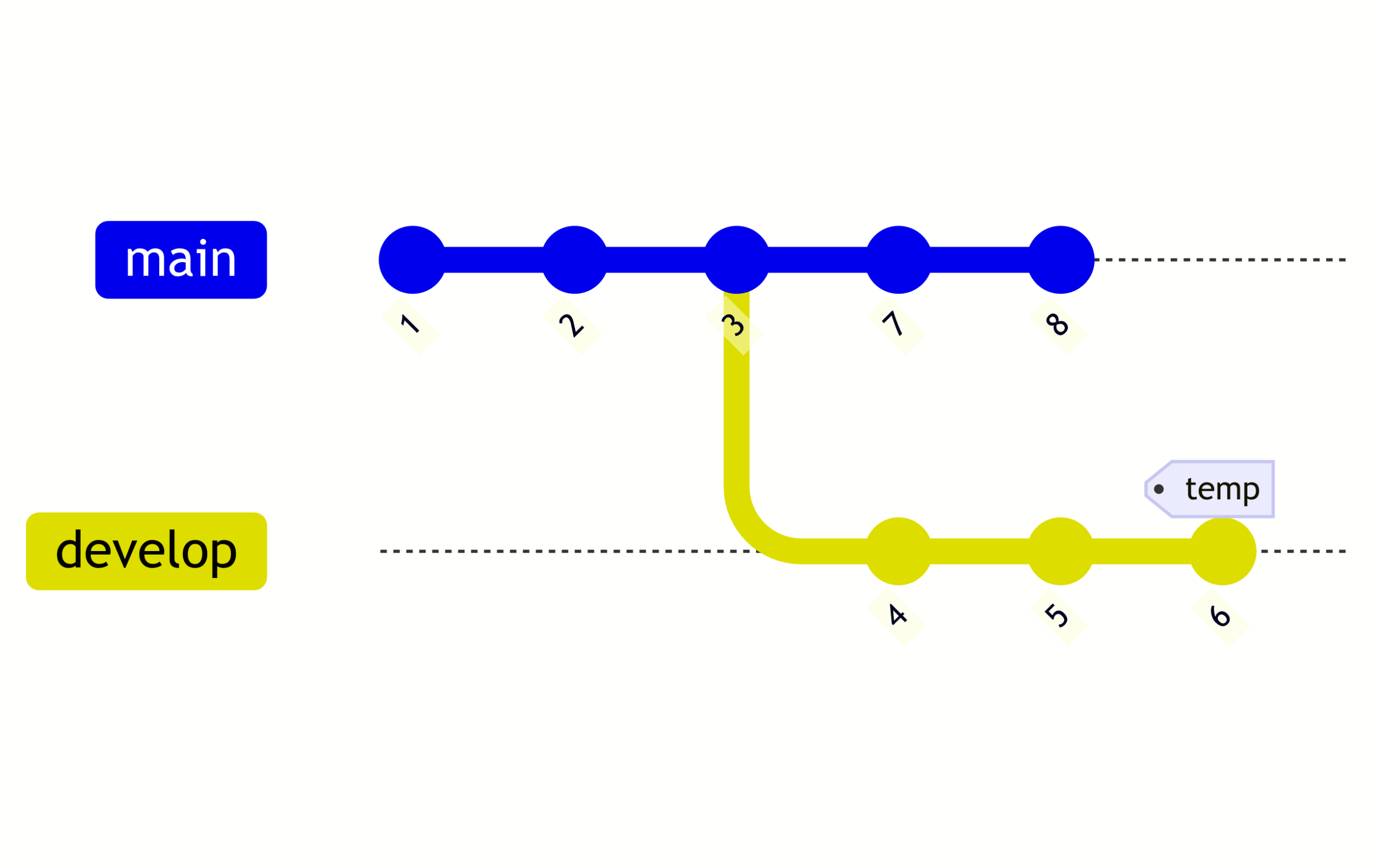
A practical walkthrough of how Icechunk uses transactions and conflict detection to guarantee data consistency when multiple processes write concurrently. The post demonstrates optimistic concurrency control and the rebase workflow using a bank-account transfer example.
Why traditional scientific file formats like NetCDF perform poorly on cloud object storage, and how cloud-optimized formats like Zarr and Icechunk solve the problem by separating metadata and chunking data.
Demystifying how S3 prefix sharding actually works and demonstrating that Icechunk can scale to hundreds of thousands of requests per second, far beyond the single-prefix limit.
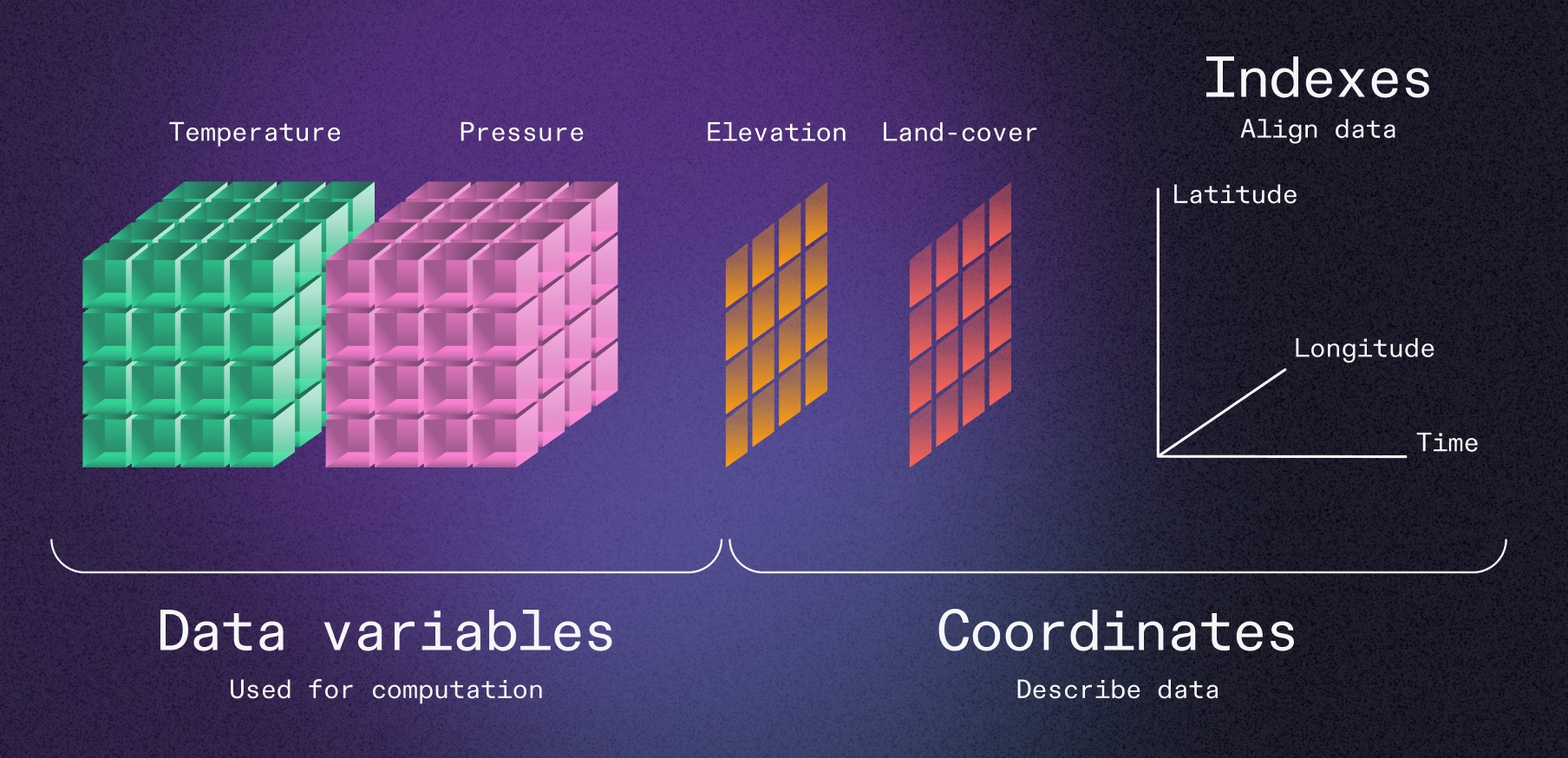
Multidimensional array data about the physical world is fundamentally incompatible with the tabular data model. Benchmarks show that array-native tools like Xarray and Zarr outperform DuckDB and Parquet by up to 10x for common weather data queries.
Earthmover and Development Seed partnered with NASA to pilot Icechunk, an open-source tensor storage engine that enables 100x faster cloud-native data access for archival Earth science datasets without costly data migration.
Earthmover customers share how NOAA climate and weather data powers their businesses, from wildfire risk modeling and energy trading to carbon market ratings and precipitation enhancement.
zarr-python’s performance paradox Last month, we released Zarr-Python 3.0 - a ground-up rewrite of the library (read more about it in this post). Beyond the exciting new features in Zarr V3, we put a lot of work into addressing some long standing performance issues with Zarr-Python 2. With the improvements described in this blog post, we’ve achieved a 14x speedup in loading the ARCO ERA5 dataset! Zarr-Python 2 had a paradoxical performance quirk; although the library could generate massive petabyte-scale datasets, it struggled to perform well when managing large or highly nested hierarchies. For example, listing the contents of a large Zarr group could be painfully slow, particularly if that Zarr group was stored on a high latency storage backend. Zarr users would experience this as long
Vector data cubes extend the familiar raster data cube concept to geospatial vector data, using arrays indexed by geometries instead of gridded coordinates. The Xvec package brings this capability to Xarray, enabling powerful multidimensional analysis of point, line, and polygon data.
A practical guide to building planetary-scale Earth observation datacubes in Zarr using serverless computing, comparing frameworks like Coiled, Modal, and Lithops for massively parallel satellite image processing.
The Zarr-Python project is undergoing a major refactor toward version 3.0, bringing full support for the Zarr V3 specification, new asynchronous APIs for better performance, and a modernized plugin system for codecs and storage backends.
A practical guide to building a high-performance PyTorch dataloader that streams Zarr data directly from cloud storage using Xarray, Xbatcher, and Dask, achieving a 15x speedup over naive approaches.
Earthmover was founded to build a modern cloud data stack for scientific data, inspired by the success of the Pangeo open-source community and the urgent need for better tooling around multidimensional array datasets in climate tech and beyond.