Expanding the Earthmover Data Marketplace: Sylvera, Spire, Eagle Rock and Carbonplan

COO
When we launched the Earthmover Data Marketplace in January, we described it as just the beginning. Today, we’re showing that growth.
We’re excited to announce four new data partners joining the marketplace: Sylvera, Spire, Eagle Rock Analytics, and CarbonPlan. This second cohort adds proprietary data fueled models in the persistently challenging field of sub seasonal forecasting (Spire) and expands the marketplace in an important new direction: beyond weather and atmospheric forecasting into Earth observation, forest carbon, wildfire risk, and high-resolution regional climate projections. Together, these datasets serve the growing community of teams building at the intersection of climate risk, infrastructure resilience, and carbon accountability.
The momentum is real. In the two months since the Marketplace launched, we’ve watched data teams across energy, insurance, agriculture, and climate risk discover that accessing production-grade ARCO data — no ingestion required, no ongoing maintenance — fundamentally changes what they can build and how fast they can build it. These four new partners deepen that value considerably.
What’s New
Sylvera: Biomass Atlas
Forest carbon accounting has long been hampered by the limitations of traditional field measurement: small plot sizes, poor georeferencing, and allometric models that often bias toward small trees and systematically underperform on large-canopy tropical forests.
Sylvera’s Biomass Atlas takes a different approach. Their dataset provides spatially and temporally explicit estimates of forest aboveground biomass density (AGBD) and canopy height at 30m resolution on an annual cadence from 2000 to the present, with pixel-level uncertainty estimates throughout.
The distinguishing feature is the underlying reference data: Sylvera has pioneered the use of Multi-Scale LiDAR (MSL), a peer-reviewed method combining terrestrial laser scanning at plot scale with UAV and airborne LiDAR upscaling, covering more than 250,000 hectares of forests worldwide, representing over $10 million in data acquisition and processing. Conventional allometry often introduces significant uncertainty—ranging from 15% to 30%—into AGBD estimations. In contrast, MSL technology achieves a 3% error margin and is unbiased against destructive measurements. These high-quality MSL datasets offer the most accurate foundation available for training Biomass Atlas earth observation models.

Courtesy: Sylvera
The result is a dataset suitable for carbon project monitoring, jurisdictional REDD+ accounting, and AI model training at a scale and accuracy that was previously unavailable in a ready-to-use format.
Key variables:
above_ground_biomass_density,canopy_heightabove_ground_biomass_density_standard_error,canopy_height_standard_error- Binary masks for gap-filled and MSL-calibrated pixels
A 180,000-hectare sample covering Pará, Brazil is available for immediate exploration. Full global dataset access is available on request.
Spire: AI-Driven Sub-Seasonal-to-Seasonal Forecasts
The 6–46 day forecast range has long been the hardest horizon to get right — too far out for numerical weather prediction to be skillful, too near-term for seasonal climate models to be useful. Spire’s AI-S2S model was built specifically for this gap.
Spire’s sub-seasonal-to-seasonal forecast system runs daily, producing 200 ensemble members out to 46 days on a 0.5° global grid, designed and trained entirely in-house, independent of any external physical or AI-based forecast system. The model is trained and fine-tuned on ERA5 reanalysis, ECMWF IFS analyses, and Spire’s proprietary data, with all inputs processed into daily statistics prior to training. The result is a fully probabilistic forecast product that gives users a rich picture of uncertainty at extended range.

Courtesy: Spire
The dataset is organized into four Zarr groups — ensemble mean and standard deviation (mean_stddev), percentile distributions (percentiles), climatological probability forecasts (probabilities), and anomalies relative to ERA5 1991–2020 climatology (anomalies) — covering surface and upper-air variables including temperature, wind, precipitation, pressure, radiation, geopotential height, and specific humidity across four pressure levels. Each variable is chunked at (1, 1, 361, 720) along the reference time, step, lat, and lon dimensions, meaning a single global map is always a single-chunk read.
The dataset updates daily on a rolling 15-issuance window, making it well-suited for operational energy trading, agricultural planning, and insurance risk pricing workflows that depend on fresh extended-range outlooks every morning.
Eagle Rock Analytics: WRF Dynamically Downscaled Climate Projections
California’s energy system faces myriad decisions about grid infrastructure, building codes, and demand forecasting that require understanding climate conditions not at a global scale, but at a neighborhood and subregional scale. Eagle Rock Analytics, on behalf of Cal-Adapt, working with datasets produced at UCLA and funded by the California Energy Commission and the Amazon Sustainability and Diversity Initiative, has contributed exactly that.
Their WRF dataset provides dynamically downscaled CMIP6 projections at 3 km, 9 km, and 45 km resolutions over California, WECC, and the Western United States respectively — across four climate scenarios (historical, SSP2-4.5, SSP3-7.0, SSP5-8.5), eight carefully selected GCMs, and three temporal resolutions (hourly, daily, monthly). The data is produced using the Weather Research and Forecasting (WRF) model, which preserves dynamical consistency across variables — temperature, wind, humidity, and pressure are always physically coherent with each other, unlike statistical downscaling methods where variables are processed independently.
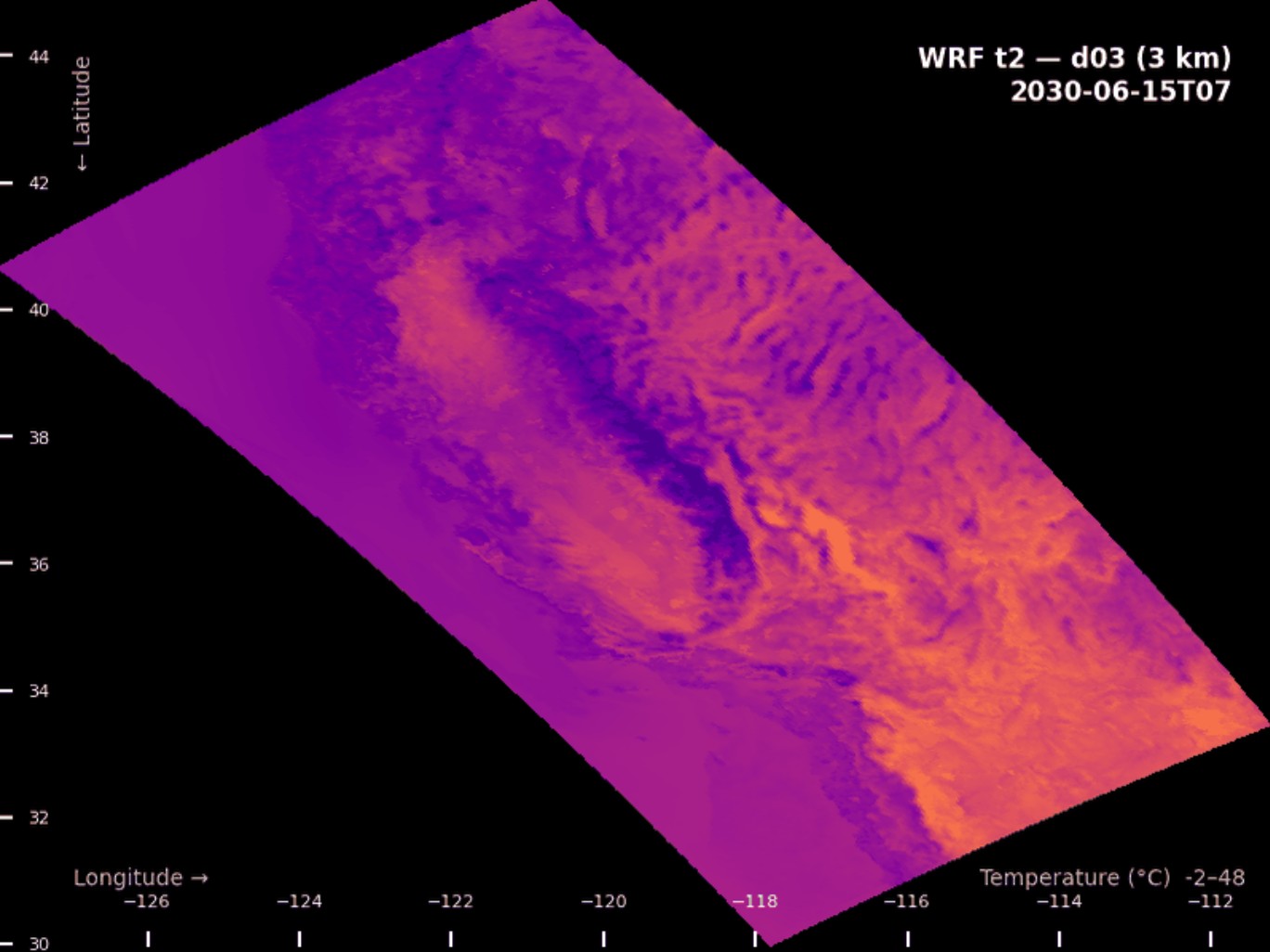 Courtesy: Eagle Rock Analytics
Courtesy: Eagle Rock Analytics
Five of the eight GCMs include a-priori bias correction against ERA5 reanalysis, and are the recommended starting point for energy sector applications. The dataset is structured as a single Icechunk repository with hierarchically organized Zarr groups, chunked to support both spatial snapshot queries and point time series efficiently.
This dataset is central to California’s Fifth Climate Change Assessment and supports use cases from heating and cooling degree day analysis to WECC-wide grid reliability planning.
Key variable highlighted: t2 — air temperature at 2m, covering 1980 through 2099.
CarbonPlan: Open Climate Risk Wildfire Dataset
As wildfire risk has moved from a regional concern to a foundational input for property insurance, energy infrastructure planning, and municipal resilience, the need for reproducible, open, methodologically transparent risk datasets has grown alongside it.
CarbonPlan’s Open Climate Risk wildfire dataset delivers exactly that. It provides wildfire risk estimates across the contiguous United States at 30 meter resolution, with two time horizons — approximately 2011 and 2047 — enabling direct comparison of how risk is projected to shift under climate change. The dataset is built entirely on free, public input data and is fully reproducible, making it suitable for regulated use cases where auditability matters.
Core variables include annual burn probability (bp_2011, bp_2047) and annual relative risk to potential structures (rps_2011, rps_2047), alongside reference variables for cross-validation. Data is provided in the WGS84 CRS at ~0.00028 degree resolution and chunked regionally for efficient access.
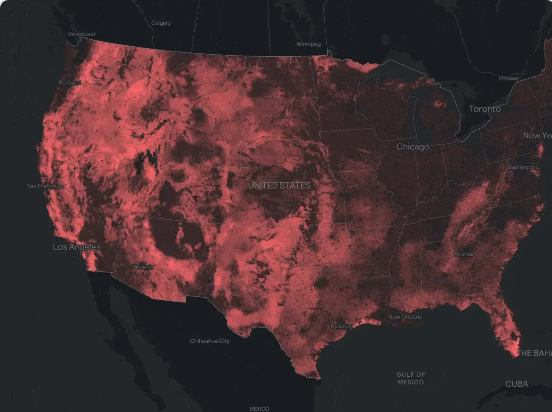 Courtesy: CarbonPlan
Courtesy: CarbonPlan
This is a natural complement to the climate projection data now available through Eagle Rock on the marketplace — together they give teams a path from physical climate projections to actualized risk estimates at the asset level.
Why This Cohort Matters
Our first cohort established the marketplace as the home for production-grade weather and atmospheric forecast data. This cohort signals something broader: the Earthmover Data Marketplace is becoming the central access point for the full range of environmental datasets that climate-aware applications require — from forest carbon and wildfire risk to high-resolution regional projections and Earth observation.
Every dataset in the marketplace is available in Icechunk format, meaning it integrates directly into Xarray and Zarr workflows with no custom ingestion. Subscribers receive incremental updates via Icechunk’s ACID transaction model, and all data is accessible through the same consistent API regardless of the underlying provider.
If you’re building in energy, insurance, climate risk, or carbon markets, these datasets are ready for you now. Go ahead: Explore the marketplace.
And if you have a dataset that belongs here, reach out. We’re onboarding new providers continuously.
COO